ReachPredict3D: A Software Platform to Robustly Extract 3-D Reaches¶
Predicting individual marker positions in a high-throughput manner is a requirement for thoroughly analyzing reaching behavior. In order to predict positions accurately, we use a pre-trained DeepLabCut network to generate positional inferences for user-defined markers. In all, we continuously label 27 unique markers across each experimental video. Our Lab’s Markers ^^^^^^^^^^^^^^^^^^^ Handle, Back Handle, Nose, Shoulder 1, Forearm 1, Wrist 1, Palm 1, Index Base 1, Index Tip 1, Middle Base 1, Middle Tip 1, Third Base 1, Third Tip 1, Fourth Base 1, Fourth Tip 1, Shoulder 2, Forearm 2, Wrist 2, Palm 2, Index Base 2, Index Tip 2, Middle Base 2, Middle Tip 2, Third Base 2, Third Tip 2, Fourth Base 2, Fourth Tip 2
DeepLabCut and 3-D Reconstruction¶
DeepLabCut (https://github.com/DeepLabCut/DeepLabCut) utilizes unsupervised deep learning methods to generate user-defined positional predictions. For our lab’s use, we track 27 unique body parts inside of our behavioral experiments. These body parts are across the entire animal, and include major markers of both hands and general animal position.
DeepLabCut requires an initial investment of training labels (~1000 per camera has worked for our DLC networks) for highly accurate positional inferences. Our lab’s benchmarked network is below, as well as some experimental results.
DeepLabCut is run across each of our experimental videos. The results are saved in a .csv file as well as in the NWB format. These .csv files form the backbone of our positional data: These are the files that we use to create 3-D positions.
Current Lab BenchMarks of DeepLabCut¶
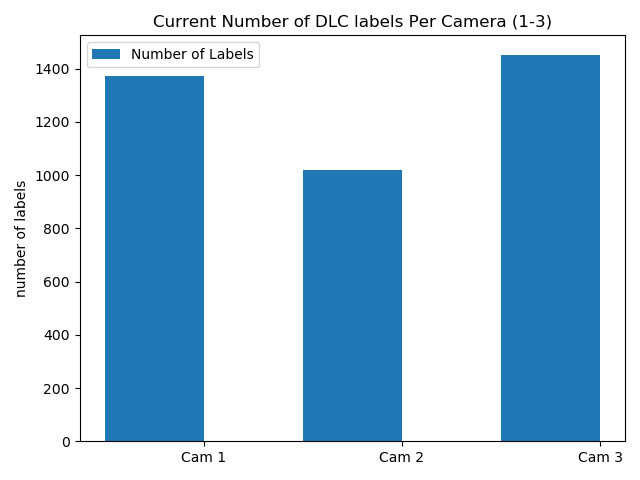
Currently, for our pilot data we have constructed a network containing 3,360 images across 3 cameras. These labels are broken down below!
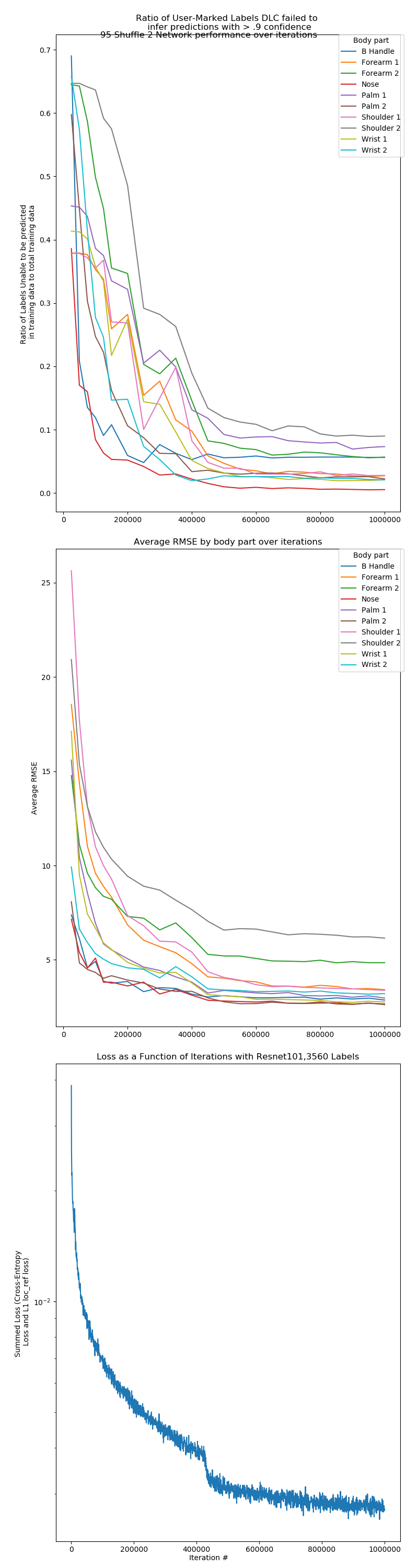
Basic benchmarks for a resnet-101 with generic network configuration are shown as well. We choose to use the 500,000 training iteration to output predictions for our reaching behaviors.
2-D Filtering¶
Generally our network produces reliable positional predictions during reaching behaviors, but in the case of outliers we adapt a 2-D filtering scheme that takes into account both positions and camera probabilities for a given camera. While our benchmarks of DeepLabCut inspire confidence that there are few outliers in predictions, smoothing our 2-D estimates is an excellent way to smooth our generated 3-D trajectories or time-series components of reaching behavior. Filtering is toggleable post-prediction during 3-D reconstruction.
3-D Reconstruction¶
Once we have filtered our positions in 2-D camera space, we are now able to reconstruct our 2-D coordinates into an appropriate 3-D euclidean space with high temporal (ms) and spatial (mm) resolution. Our lab uses DLT to reconstruct our coordinates into a proper euclidean space. DLT is a robust, established method that utilizes linear transformations between vector spaces to create a robust and accurate re-creation of the 3-D euclidean space our camera’s obtain. For more information about specific camera calibration routines, see our DLT camera calibration tutorial.
We are able to reconstruct our 3-D coordinates with a set of vector co-efficients obtained from the DLT routine. These co-efficients contain the effective translation and rotation of our camera system in the 3-D space. To obtain 3-D coordinates for a given experimental session, we may run a function (extract_kinematics) that requires a root directory, dlt calibration co-efficients, and a save directory. Inside of our root directory, we require that the video .mp4 files for a given experimental session’s camera be in the same folder. The resulting .csv predictions (filtered or unfiltered) are then translated into 3-D using the experimentally derived DLT co-efficients, then saved to our specified save directory.
Our lab also saves a copy of these 3-D predictions to a local Neurodata Without Borders (NWB) file, using the Reaching Without Borders pipeline.